Run Cloud-Scale AI
on Your Desktop
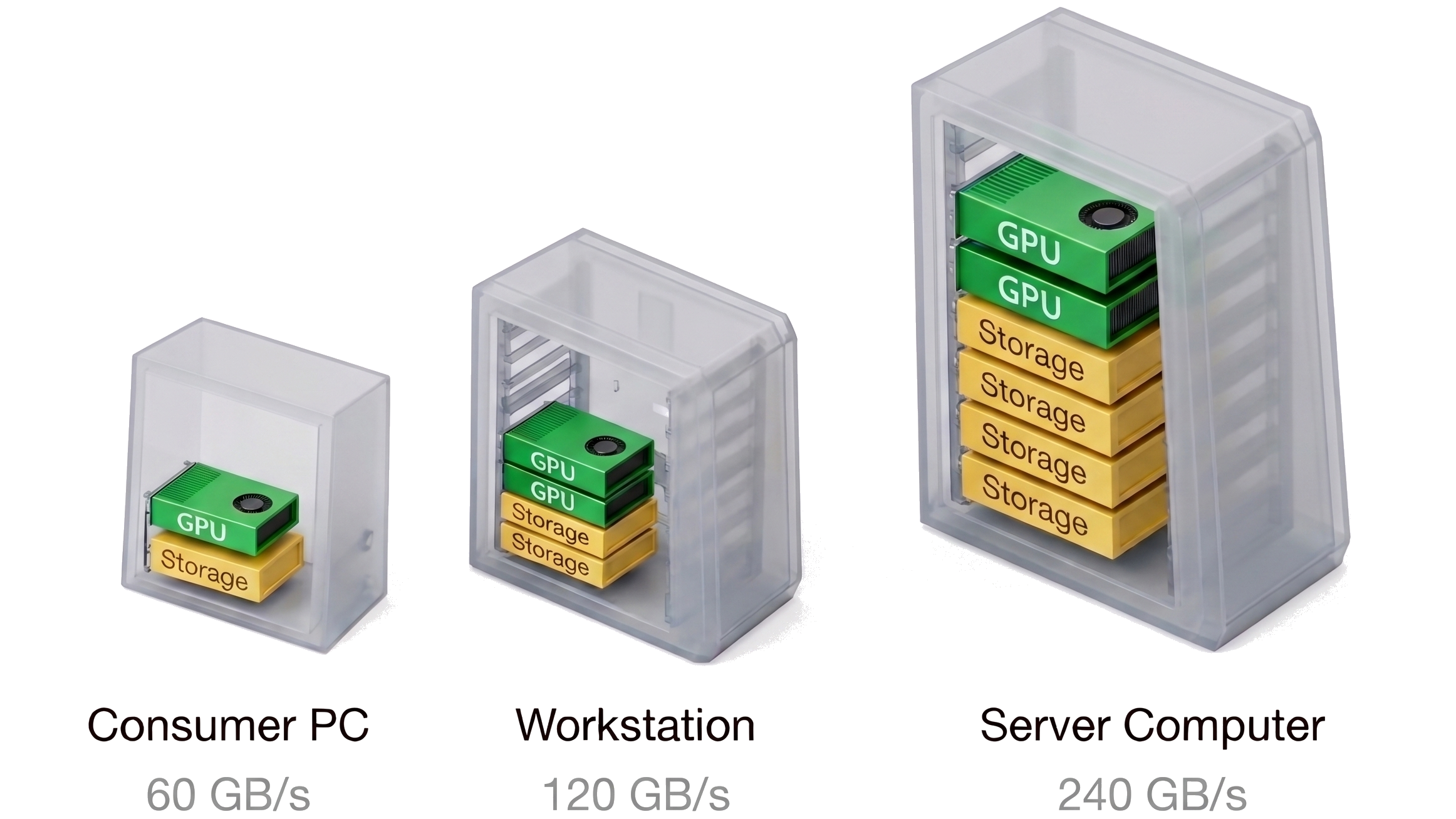
Cloud-scale AI models on commodity hardware. Slash infrastructure costs by 20x. No GPU cluster required.
20x +
Cost Reduction
From $5K
vs $300K+ GPU Clusers
15-20
tokens per second