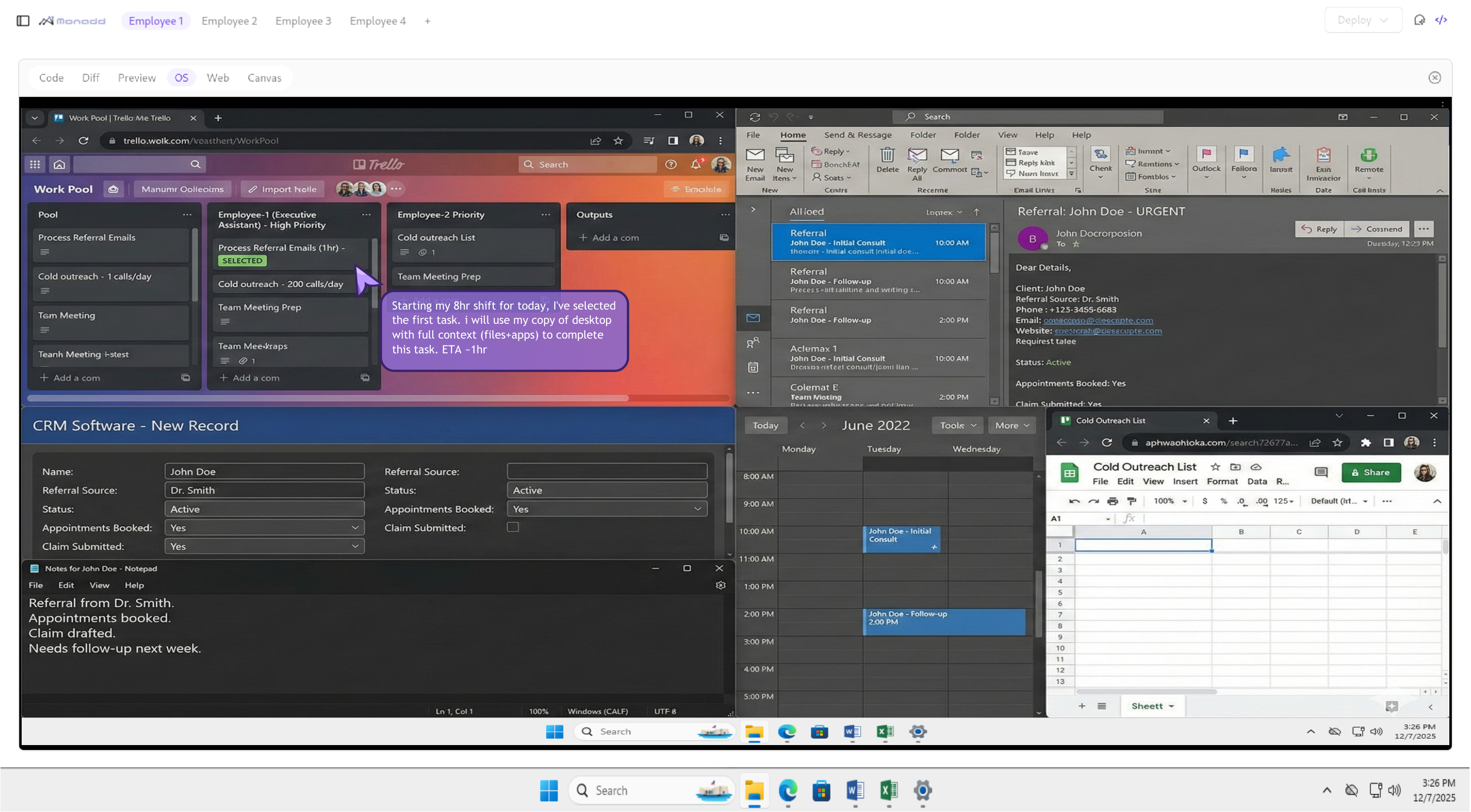
Monadd-AI decouples intelligence from the cloud, giving AI its own desktop to operate your software, complete end-to-end workflows, and work a full 8-hour day.
We give the AI its own virtualized desktop, allowing it to operate your existing software just like a human would—no APIs required.
Your virtual employee shares your desktop, apps, and files, operating your software in the same environment you do.
Meet major data regulations by keeping your data and AI models on-device and under your control.
Assign a complex, multi-step task and let it run from end to end. The AI works autonomously to complete the job.
You're always in charge. Approve, correct, or take over at any step. The system learns from your feedback.
Low-latency perception-action loops mean your virtual employee can react and operate at human speed, without frustrating delays.
A fixed subscription replaces unpredictable, metered micro-actions. You get an employee, not a runaway cloud bill.
Leverage the most advanced frontier AI models for best-in-class professional output. Monadd-AI's proprietary technology runs 100B to 1T parameter models on Monadd's AI-PCs (or equilvantly powerful PCs), giving you unparalleled performance while satisfying the strictest compliance requirements.

OpenAI

Qwen

Moonshot

DeepSeek

Z AI

Meta

Mistral AI
Qwen
OpenAI
Qwen
Moonshot
DeepSeek
Z AI
Meta
Mistral AI
Qwen
Every business runs on computer work: clicks, forms, portals, and spreadsheets. Copilots help you type faster. Virtual employees finish the workflow.
Answer questions from a knowledge base.
Assist with tasks inside one application.
Execute end-to-end workflows across all your applications.
A concrete example: processing a new client referral from email to a lodged claim, all done autonomously.
Monadd-AI monitors your inbox, identifies a new referral email, and extracts the client details and attached documents.
It opens your practice management software and creates or updates the client record with the extracted information.
The virtual employee checks your calendar, proposes available times, and books the initial appointment.
It prepares the necessary intake forms and drafts initial notes in the correct client template.
They hit three walls when they try to operate GUIs all day long.
Every perception-action loop becomes a slow, frustrating round-trip to the cloud. A virtual employee needs thousands of micro-actions; if each one is a cloud call, you get slow, expensive, and brittle agents.
"Per action / per token" economics explode for long-running work. An agent averaging 1 action/sec for 8 hours a day would perform over 28,000 actions. Metered pricing makes this untenable.
Constant reliance on the cloud introduces friction from rate limits, network dropouts, and privacy or compliance hurdles, preventing the agent from compounding knowledge and truly owning a workflow.
Low-latency perception-action loops mean your virtual employee can react and operate at human speed, without frustrating delays.
A fixed subscription replaces unpredictable, metered micro-actions. You get an employee, not a runaway cloud bill.
Your virtual employee works reliably, even with flaky or intermittent internet connectivity, ensuring workflows are always completed.
On-device processing isn't an ideology; it's an economic and performance necessity for AI labor.
Low-latency perception-action loops mean your virtual employee can react and operate at human speed, without frustrating delays.
A fixed subscription replaces unpredictable, metered micro-actions. You get an employee, not a runaway cloud bill.
Your virtual employee works reliably, even with flaky or intermittent internet connectivity, ensuring workflows are always completed.
Monadd-AI is architected to help you meet major data legislation like GDPR, HIPAA, and FINRA by processing data and running AI on-device.
We never track, log, or analyze how you use Monadd-AI. There are no hidden analytics or background data collection.
Achieve best-in-class results without cloud dependency. By running frontier models locally, you get the power of sophisticated AI with the security and compliance of a true on-premise solution.
Everything is stored on your device—no exceptions. Your chats, models, settings, and prompts live on your local machine, not our servers, giving you complete data sovereignty.
Because your data and models stay on your device, you inherently reduce risk and simplify compliance audits.
People are loving Monadd-AI for its powerful features, intuitive interface, and the speed of improvements.
"Monadd-AI is an incredible tool for productivity. It offers so many unique features that make complex workflows possible."
"The flexibility among local and remote model providers is unmatched. Being able to run the same interface on my phone is a game-changer."
"It ended my journey searching for the right application. Local llm, ollama integration, rag, online data retrieval just like perplexity."
"The big difference is openweb.ui does more with less polish. Monadd-AI is more focused and everything it does it does really really well."
"I fell in love with Monadd-AI at first sight! The team is doing an amazing job with continuous improvements."
"Best front app, especially with a portrait 9/16 screen. The interface is clean and everything just works seamlessly."
From exploring ideas to scaling serious projects, Monadd-AI offers straightforward plans for every stage.
For individuals for trial
For Professionals & Power Users
Buy License (LOI)A lifetime license is available for a one-time payment of $1399, including 2 years of updates. Ideal for individuals preferring a perpetual license.
For small, collaborative teams
Buy License (LOI)Annual contract
Contact UsExplore features and pick the plan that fits how you work
Curious about Monadd-AI? We've got the answers to your most pressing questions. Let's dive in!